

Most of us probably don’t spend much time thinking about the mechanics of navigating between pages in web applications. Which is fair enough. After all, when navigation is done right and works, you shouldn’t notice it. But a few years ago there was a big change in how navigation was performed - when single page applications, also know as SPAs, came on the scene…
This is the first post, of what I’m sure will turn into a few, looking at how routing and navigation works in Blazor.
Traditional Navigation
Let’s start by understanding the traditional model for navigating between pages in web applications.
In order to load a web page we first need to make a HTTP GET request to the web server, for example by entering chrissainty.com into the address bar of a web browser. The web server is then going to respond and send us back some content such as HTML, CSS, JavaScript, etc…
The browser will parse all of the content and if all is well, load the web page. This is a simplification of the actual process, but you get the idea.
We now have a page we can view and interact with, so what happens when we want to move to another page? Most often, we click on a link to the new page which starts the whole process again. The browser makes a new request to the server and a new page and its assets are sent back and displayed.
It’s only right to point out that there are some slight changes this time. For example, some of the CSS and JavaScript might have been cached so they won’t be downloaded again. But essentially the process is the same.
In a nut shell, that’s the basics of navigation in traditional web apps. So what about SPA applications? After all, how do you navigate between pages when there is only ever one page?
SPA Navigation
The obvious point to make right from the start is that we’re not navigating between physical pages in SPA applications, as we do in traditional web apps.
What we’re doing would be better described as virtual navigation. This is achieved by dynamically adding and removing content from the DOM (document object model) depending on the route that has been requested. This is most commonly handled by some form of router provided by the particular SPA framework.
Other manipulations are also utilised to further reinforce the illusion of navigation. Things like manipulating the browsers navigation history so forward and back buttons function as expected.
So what does this look like?
When initially loading a site, not much different to traditional web apps. We make the HTTP GET request and then download the HTML, CSS, JavaScript and any other static assets.
The difference shows when we click on a link to move to a different area of the site.
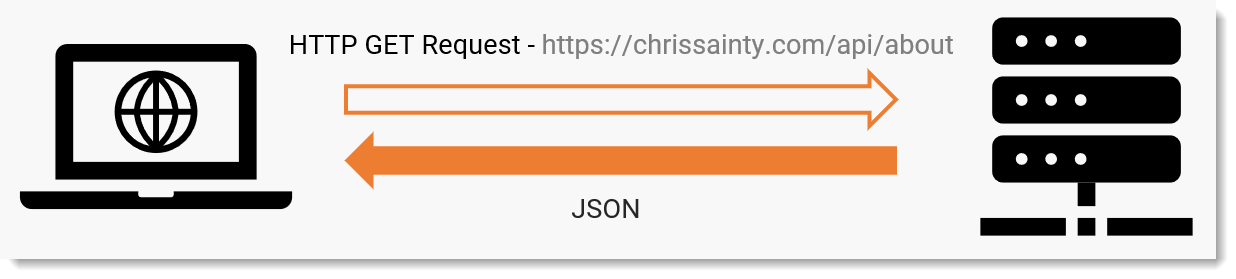
This time the payload we get back is a little different, it’s just data. Why data? It’s because SPA applications tend to download the whole application when the site is first loaded, so everything is already there. When changing between pages the only additional content that is required is the data to be displayed. In fact, depending on the page, it’s perfectly possible that a page in a SPA application might not need to make any additional request to the server at all.
I appreciate this has all been quite general and high level so far, but I wanted to cover the basics first. So let’s get into specifics and talk a bit about how routing and navigation work in Blazor.
Routing in Blazor
Similar to other SPA frameworks, Blazor has a router which is responsible for performing this virtual navigation. Blazor’s router is actually a component and you can find it in the App.razor component - the default implementation looks like this.
<Router AppAssembly="typeof(Startup).Assembly">
<Found Context="routeData">
<RouteView RouteData="@routeData" DefaultLayout="@typeof(MainLayout)" />
</Found>
<NotFound>
<LayoutView Layout="@typeof(MainLayout)">
<p>Sorry, there's nothing at this address.</p>
</LayoutView>
</NotFound>
</Router>
Discovering Page Components
In order to be able to route to different pages the router has to know what components to load for a given route. This is achieved by passing in an AppAssembly to the router. The provided assembly will be scanned when the application boots up in order to discover any components declaring a route via the @page directive.
For example, a component which had the following code declared would be loaded by the router if a request was made for mysite.com**/about**.
@page "/about"
I like to refer to these components as page components as opposed to regular components. The official docs also use the term routable components.
You can also specify additional assemblies to be scanned by using the AdditionalAssemblies parameter, which takes an IEnumerable<System.Reflection.Assembly>. This is really useful if you want to include page components from other Razor Class Libraries.
Found and NotFound Templates
Two template parameters must also be specified when declaring the router component, Found and NotFound.
The Found template is used when the router finds a page component which matches the requested route. Inside the Found template is the RouteView component. This component is responsible for rendering the correct page component based on the component type parsed to it by the router via the RouteData.
<RouteView RouteData="@routeData" DefaultLayout="@typeof(MainLayout)" />
If the page component has a layout specified then the RouteView will makes sure that is rendered as well. It does this by using the LayoutView component under the covers. A default layout can also be declared, as demonstrated in the code above. If the page component being rendered does not specify a layout then it will be rendered using the default one.
When the router is unable to find a page component which matches the requested route the NotFound template is used. By default, this shows a simple p tag with a friendly message nested inside of the LayoutView component. As you can probably guess, the LayoutView component is responsible for rendering the specified layout component. If you prefer, you could use a component instead of the p tag.
<NotFound>
<LayoutView Layout="@typeof(MainLayout)">
<MyNotFoundComponent />
</LayoutView>
</NotFound>
Handling Navigation
Now we know about how to configure the required parts of the router let’s wrap this post up by covering how it actually handles navigation. This version will be quite high level still as I’ll deep dive into this process in future posts.
When a link is clicked, that event is intercepted by Blazor, in the JavaScript world. This event is then passed into the C# world to the NavigationManager class. This in turn fires an event, with some metadata, which the router component is listening for.
The router handles this event and uses the data supplied to check for any page components which match the requested route. If the router finds a match it will render the Found template we looked at, passing it the RouteData - which contains the type of component to render and any parameters it requires. If a match couldn’t be found then the router will render the NotFound template.
There is one other scenario which I haven’t mentioned yet, which is how does the router know when to intercept a navigation event and when not to? This is controlled by the <base href> tag defined in the _Host.cshtml or index.html. If a link which was clicked has a href which falls within the base href then Blazor will intercept the event. If it doesn’t then Blazor will trigger a normal navigation.
Summary
We’ll leave things there for this post. Next time we will dive into the detail of what is going on behind the scenes and understand each part of the navigation and routing process in Blazor.
In this post, we have taken a preliminary look at routing in Blazor. We started by covering off the basics, understanding how navigation happens in traditional web applications vs SPA applications. Before looking at Blazor specifically, covering the default router setup and a high level overview of how Blazor handles a navigation event.
